Previous courses covered SQL databases (RDBMS) and data manipulation frameworks in R and Python.
Last time, we:
Introduced the NoSQL ecosystem.
Introduced MongoDB, a document-oriented NoSQL database.
Explored simple queries in MongoDB.
Utilized PyMongo for interacting with MongoDB.
Our Goals
By the End of This Module, We Will Be Able To:
Formulate data analysis tasks for MongoDB based on understanding of user needs.
Implement flexible data analysis pipelines using MongoDB Aggregation Framework.
Analyze tool suitability for the particular task by synthesizing data aggregation knowledge across MongoDB, SQL, and dplyr/pandas.
By the End of This Course, We Will Be Able To:
Prototype an analytical app for a music streaming service using MongoDB to provide insights to the users based on aggregated user preferences and listening history data.
Case Study: Prototyping an Analytical App for a Music Streaming Service
Prototype an analytical app for a music streaming service using MongoDB, including aggregating user preferences and listening history data to provide insights to users.
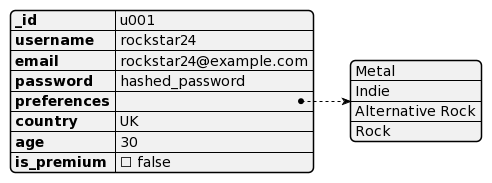
users
tracks
listeningHistory
User-Centered Perspective
Difficult to think as a user…
Simulating realistic interactions is a way.
Prototyping user-facing app with realistic data might help!
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: pymongo in /cloud/python/lib/python3.8/site-packages (4.6.1)
Requirement already satisfied: dnspython<3.0.0,>=1.16.0 in /cloud/python/lib/python3.8/site-packages (from pymongo) (2.6.1)
[notice] A new release of pip is available: 23.0.1 -> 24.0
[notice] To update, run: /opt/python/3.8.17/bin/python3.8 -m pip install --upgrade pip
Look at the data and think about the case in general.
Write down some reasons why MongoDB can be relevant (or not!) for our case in your worksheet.
Case: Prototype an analytical app for a music streaming service using MongoDB, including aggregating user preferences and listening history data to generate meaningful statistics for two separate stakeholders.
nosoc.io/ubc-worksheet
So, Why Might This Problem Require MongoDB?
Nested flexible structures.
Frequent schema changes.
Flexible analytics pipelines.
We inherited it.
Some considerations to keep in mind:
No silver bullet.
Complex choice between SQL-based, Hadoop-based, and other analytical solutions.
Extra work to connect BI tools (e.g., Tableau) to MongoDB.
Our Main Tool: MongoDB Aggregation Framework Pipeline
Approaches to querying MongoDB:
Basic queries (.find()) we covered last time.
MongoDB Aggregation Framework.
Geospatial queries.
Full text search.
Vector engine.
Map-Reduce.
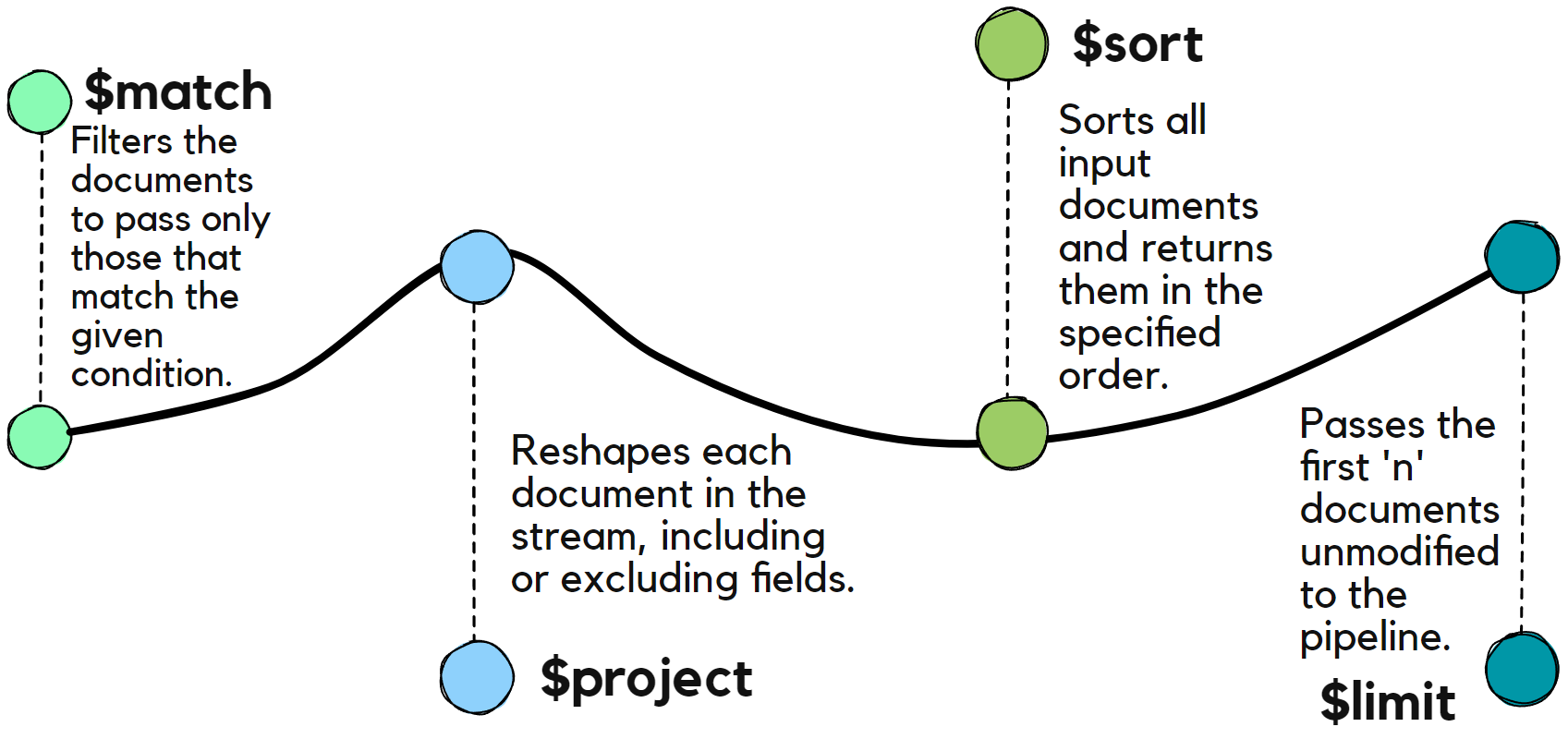
Simple Pipeline
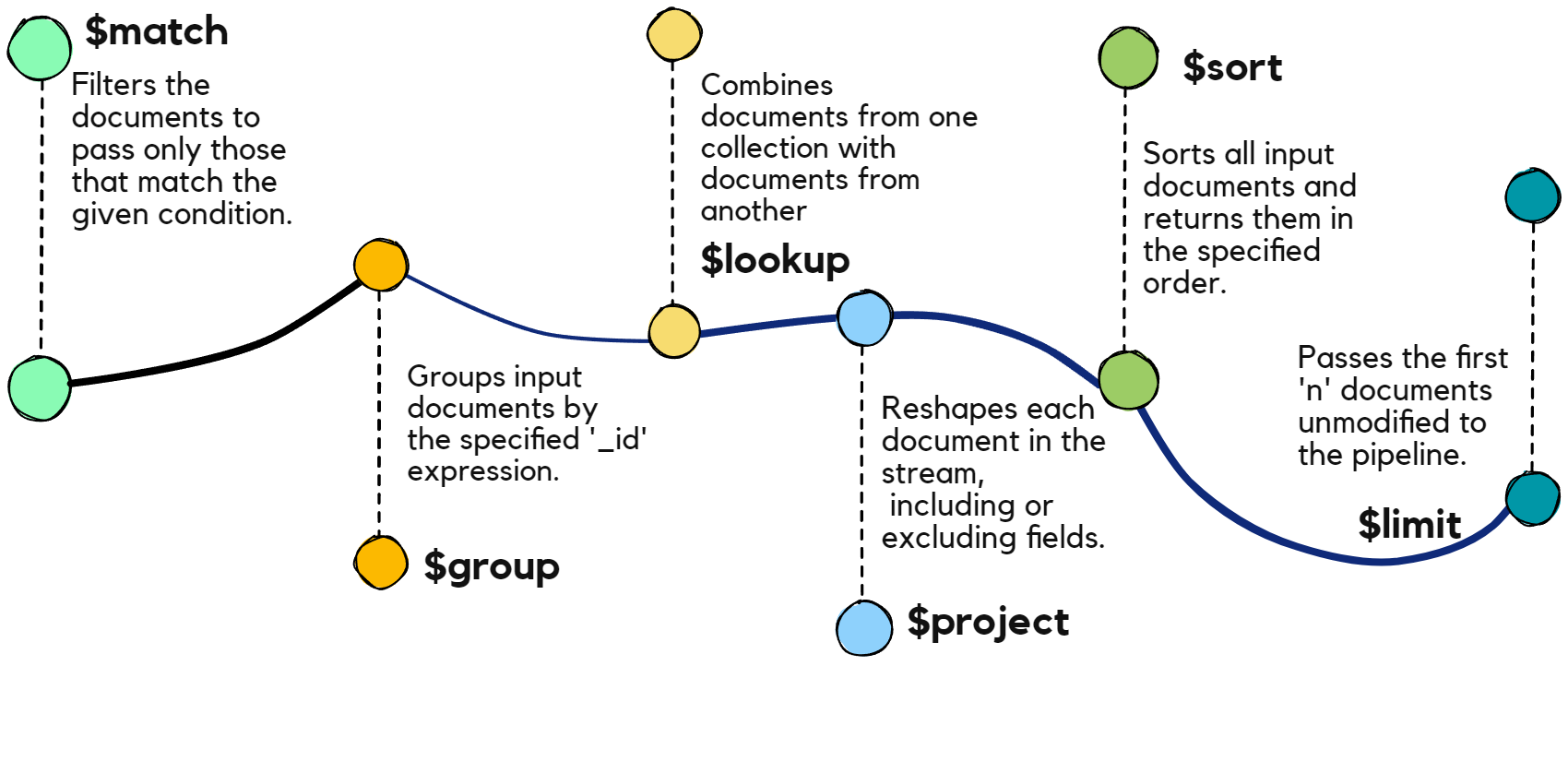
$match Stage
Filters documents to pass only those that match the specified condition.
Examples:
{"$match": { "country": "UK" }}
{"$match": { "age": {"$lt": 25}}}
$project Stage
Reshapes documents by including, excluding, or renaming fields.
Examples:
{"$project": {"genre": 1, "_id": 0}}
$sort Stage
Sorts documents based on specified fields.
Example: {"$sort": { "age": -1 }}
$limit Stage
Limits the number of documents passed to the next stage.
Example: {"$limit": 5}
Composing A Simple Aggregation Pipeline
MongoDB Pipeline Checklist
Tip
Define stages and expected inputs and outputs.
What order do we want them to be in, and why?
Do we need to use some stages more than once?
In your code, first define every stage and assign it to a separate variable.
Define your pipeline(s) step-by-step.
Example Pipeline
Let’s explore how to build a simple pipeline for showing the artist, genre, and year of tracks in our database created after 2015. Let’s limit the results to the latest 3 tracks. code
tracks = db.trackslimit3 = {"$limit": 3}match1 = {"$match": {"year": {"$gt": 2015}}}project1 = {"$project": {"artist": 1, "_id": 0, "genre": 1, "year": 1}}sort1 = {"$sort": {"year": -1}}def run_print_short_pipeline(connection, collection, pipeline): result = connection[collection].aggregate(pipeline) pprint.pprint(list(result)) #NB! do not use with large result setspipeline1 = [match1, project1, limit3, sort1]pipeline2 = [match1, project1, {"$limit": 10}, sort1]pipeline3 = [ {"$limit": 10}, match1, project1, sort1]run_print_short_pipeline(db, 'tracks', pipeline1)run_print_short_pipeline(db, 'tracks', pipeline2)run_print_short_pipeline(db, 'tracks', pipeline3)# result = db.tracks.aggregate(pipeline1)# # # for doc in result:# # pprint.pprint(doc)# # pprint.pprint(list(result)) #NB! do not use with large result sets
Think for 2 minutes and write them down in your worksheet.
Discuss ideas in groups of 2 or 3 with your neighbors for 3 minutes.
Update your notes.
nosoc.io/ubc-worksheet
Recap
Pipeline Stages
Pipeline Design Checklist
Define stages and expected inputs and outputs
What order do we want them to be in, and why?
Do we need to use some stages more than once?
In your code, first define every stage and assign it to a separate variable
Define your pipeline(s) step-by-step
Activity 6. Insights for Our Users
Finally, let’s generate some ideas of useful features we can prototype for our users!
Think for 2 minutes about what needs of users we can support with our data, relying on the tools we learned.
Discuss ideas in groups of 2 or 3 with your neighbors.
Write down the 2 ideas you like most in your worksheet.
nosoc.io/ubc-worksheet
That is all for today!
Instructional Notes and Reflection
What Would’ve Been Covered in the Next Part of an Hour Lecture and During the Lab?
Aggregation operators.
Extra stages (e.g., $sample, $set, $unset).
Operations on nested structures (e.g., $unwind, $group + $push, $addToSet).
Optimization and Indexing, explain.
Evidence-Informed Learning Design Approaches
Warm-up task helps to retrieve schemata and provide spaced practice.
Live coding + task and process worked examples.
High-level conceptual tasks (Parson’s problems, mix and match).
Think-pair-share activities + Active Learning Worksheet.
Educational Technology and Scalability
Automating Active Learning Worksheets
Partial automatic grading for immediate feedback.
Backchannel with TAs/instructor during the class.
(Bi-gram) wordclouds.
Other Tools for Scalability and Practice
Dropdowns with contextual actions, hints, reflection prompts.
Mindful learnersourcing of examples and motivational prompts.
Authentic Tasks and Cross-course Connections
This module can be a part of Databases, ML Systems, Web and Cloud Computing courses.
Designing/re-designing the course around cases/authentic tasks (cf. 4C/ID model) can help form complex skills relying on indirect import from other courses, e.g.,